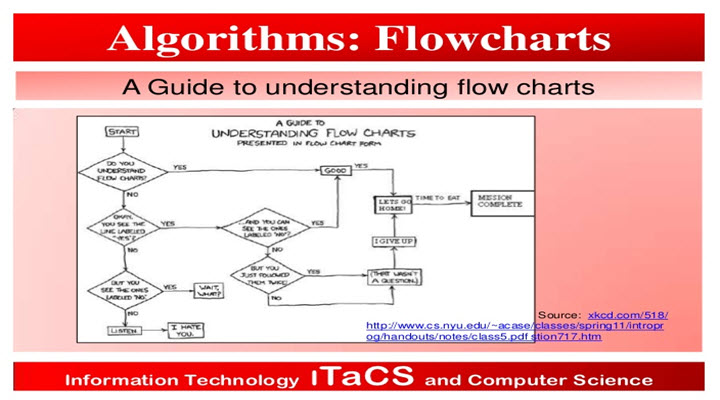
JavaSript
از ویکیپدیا، دانشنامهٔ آزاد
جاوااسکریپت (به انگلیسی: JavaScript) زبان برنامهنویسی اسکریپت مبتنی بر اشیاء است که توسط NetScape تولید شدهاست. این زبان، یک زبان شیگرا[۱] است که بر اساس استاندارد ECMA-262 Edition 3 نوشته شدهاست.
علیرغم اشتباه عمومی، زبان جاوااسکریت با زبان جاوا ارتباطی ندارد، اگر چه ساختار این زبان به سی پلاس پلاس(++C) و جاوا شباهت دارد؛ که این امر برای یادگیری آسان در نظر گرفته شدهاست. از همینرو دستورهای متداول مانند if, for,try..catch ,”while” و… در این زبان هم یافت میگردند.
این زبان میتواند هم به صورت ساخت یافته و هم به صورت شی گرا مورد استفاده قرار گیرد. در این زبان اشیاء با اضافه شدن متدها و خصوصیات پویا به اشیاء خالی ساخته میشوند، بر خلاف جاوا. بعد از ساخته شدن یک شی به روش فوق، این شی میتواند به عنوان نمونهای برای ساخته شدن اشیاء مشابه مورد استفاده قرار گیرد.
به علت این قابلیت زبان جاوااسکریپت برای ساختن نمونه از سیستم مناسب میباشد.
کاربرد گسترده این زبان در سایتها و صفحات اینترنتی میباشد و به کمک این زبان میتوان به اشیاء داخل صفحات HTML دسترسی پیدا کرد و آنها را تغییر داد. به همین علت برای پویا نمایی در سمت کاربر، از این زبان استفاده میشود.
JavaScript به صورت «جاواسکریپت» خوانده میشود، ولی در فارسی به صورت «جاوااسکریپت» ترجمه میشود و اگر به صورت «جاوا اسکریپت» ترجمه شود اشتباه است چون دو کلمه جدا از هم نیست و اگر به صورت دو کلمه جدا نوشته شود خطلاهای نگارشی ایجاد میشود، به طور مثال ممکن است کلمه جاوا در انتهای خط و کلمه اسکریپت در ابتدای خط بعدی نوشته شود.
تاریخچه
جاوااسکریپت را در ابتدا شخصی به نام برندان ایچ در شرکت نتاسکیپ با نام Mocha طراحی نمود. این نام بعداً به LiveScript و نهایتاً به جاوااسکریپت تغییر یافت.[۲] این تغییر نام تقریباً با افزوده شدن پشتیبانی از جاوا در مرورگر وب Netscape Navigator همزمانی دارد. اولین نسخهٔ جاوااسکریپت در نسخه ۲٫۰B3 این مرورگر در دسامبر ۱۹۹۵ معرفی و عرضه شد. این نام گذاری منجر به سردرگمیهای زیادی شده و این ابهام را ایجاد میکند که جاوااسکریپت با جاوا مرتبط است در حالی که این طور نیست. عدهٔ زیادی این کار را یک ترفند تجاری برای به دست آوردن بخشی از بازار جاوا که در آن موقع زبان جدید مطرح برای برنامهنویسی تحت وب بود میدانند.[۳][۴]
به دلیل موفقیت عمدهٔ جاوااسکریپت در نقش زبان نویسهای سمت کاربر (client side scripting language) برای صفحات وب، مایکروسافت یک نسخه سازگار از این زبان را ایجاد کرد و به علت مشکلات حقوقی آن را جی اسکریپت نامید. این زبان در نسخه ۳٫۰ از مرورگر اینترنت اکسپلورر و در اوت ۱۹۹۶ داده شد. تفاوتهای این دو زبان به حدی جزیی است که اغلب جی اسکریپت و جاوااسکریپت به جای هم به کار میروند. هرچند که مایکروسافت در اینجا چند ده دلیل برای تفاوت جی اسکریپت با استاندارد ECMA مطرح میکند.
نتاسکیپ جاوااسکریپت را به سازمان Ecma International برای استاندارد سازی ارسال کردهاست و نتیجه نسخهٔ استاندارد شدهای به نام ECMA Script است.[۵]
جاوااسکریپت به یکی از زبانهای برنامهنویسی پر طرفدار در وب تبدیل شدهاست. هر چند ابتدا بسیاری از برنامه نویسان حرفهای زبان را کم ارزش تلقی میکردند چون مخاطبین آن نویسندگان صفحات وب و آماتورهای این چنینی بودند.[۶] ظهور ایجکس بار دیگر جاوااسکریپت را در معرض توجه قرار داد و برنامه نویسان حرفهای بیشتری را به خود جذب نمود. نتیجه ازدیاد فریمورک و کتابخانههای جامعی در این زمینه، بهبود شیوههای رایج برنامهنویسی در جاوااسکریپت و افزایش کاربرد جاوااسکریپت خارج از وب است.[نیازمند منبع]
امکانات زبانی
امکانات زیر (در صورت قید نشدن) همگی مطابق استاندارد ECMA Script میباشند.
فریم ورک های مبتنی برجاوا اسکریپت
فریم ورک های زیادی برای این زبان درست شده است مانند جی کوئری و آنگولار جی اس
زبان امری و ساخت یافته
جاوااسکریپت از تمامی نحو ساختاری زبان C پشتیبانی میکند. مانند گزاره (if و switch و حلقههای while و…) یک مورد استثناء تعیین حوزهٔ متغیرهاست: تعریف حوزه در حد block در جاوااسکریپت وجود ندارد. هر چند جاوااسکریپت ۱٫۷ با کلمهٔ کلیدی let این نوع حوزه دهی را امکانپذیر میسازد. مانند c در جاوااسکریپت بین عبارت و گزاره تفاوت وجود دارد.
پویایی
؛ تایپ دهی پویا: مانند اکثر زبانهای نویسهای تایپ به مقدارها منسوب میگردد و نه به متغیرها. برای مثال متغیر x ممکن است به یک عدد وابسته سازی شود، و بعداً به یک رشته. جاوااسکریپت برای تعیین تایپ شی راههای مختلفی از جمله تایپ دهی اردکی (duck typing) را دارد.[۷]
؛ تایپ دهی ضعیف: زبان جاوااسکریپت از نظر تایپ دهی ضعیف به شمار میآید و در آن نتیجهٔ عملیاتی مانند ۵ + “۳۷”، عبارت “۵۳۷” خواهد بود. (عدد را با رشته جمع کردهاست)
؛ اشیاء به دید آرایههای انتسابی: جاوااسکیرپت تقریباً تماماً بر اساس اشیاء است. اشیاء، آرایههای انتسابی به همراه یک «ساختار شماتیک» هستند. نام ویژگی اشیاء، کلیدهای آرایه انتسابی هستند و درواقع obj.x = ۱۰ با obj[“x”] = ۱۰ هم ارز هستند و شیوه نگارش با نقطه صرفاً یک سهولت نحوی است. ویژگیها و مقدارهایشان در زمان اجرا قابلیت تغییر اضافه و حذف دارند. همچنین میتوان روی ویژگیهای یک شی با ساختار for … in پیمایش کرد.
؛ ارزیابی در زمان اجرا: جاوااسکریپت یک تابع eval دارد که قادر است گزارههای تولید شده در یک رشته در زمان اجرا را، اجرا کند.
تابعی بودن
؛ تابعی بودن: توابع موجوداتی «درجه اول» محسوب میشوند، یعنی خود یک شی هستند؛ بنابراین میتوانند ویژگی داشته باشند، در آرگومانهای تابعها داده شوند و مانند هر شی دیگری با آنها رفتار شود
؛ توابع داخلی و بستارها: توابع داخلی (توابع تعریف شده داخل یک تابع دیگر) هر بار که تابع بیرونی فرا خوانده شود، ایجاد میشوند و متغیرهای توابع بیرونی تا زمانی که تابع داخلی وجود داشته باشد، وجود خواهند داشت، حتی پس از اتمام آن فراخوانی از تابع بیرونی. (مثال: اگر تابع داخلی به عنوان مقدار برگشتی تابع باشد، هنوز به متغیرهای تابع بیرونی دسترسی دارد) – این مکانیزم بستار گرفتن در جاوااسکریپت است.
ساختار شماتیک» محوری
؛ ساختار شماتیک: جاوااسکریپت به جای ردهها برای تعریف ویژگیهای اشیاء، که شامل متدها و وراثت است از «ساختار شماتیک» استفاده میکند (پیشنمونه). امکان شبیهسازی بسیاری از امکانات رده-محور با ساختارهای شماتیک جاوااسکریپت امکانپذیر است.
- توابع در نقش سازندهٔ اشیاء
برای توابع علاوه بر نقش عادی، به عنوان سازنده ی اشیاء هم عمل میکنند. آوردن یک new قبل فراخوانی تابع، آن را با کلمهٔ کلیدی this وابسته سازی شده به شی جدید اجرا میکند. ویژگی prototype از تابع مورد نظر، ساختار شماتیک شی جدید را مشخص میکند.
؛ توابع در نقش متد: بر خلاف بیشتر زبانهای شی گرا تفاوتی میان تعریف تابع و متد وجود ندارد. بلکه تفاوت در زمان فراخوانی تابع است، زمانی که یک تابع به عنوان متد یک شی فراخوانده میشود کلمهٔ کلیدی this محلی آن تابع به شی مورد نظر وابسته سازی میشود.
امکانات دیگر
- امکانات دیگر
جاوااسکریپت برای تأمین اشیاء و متدها که با آنها تعامل کند به یک محیط اجرایی (مانند مرورگر وب) نیاز دارد تا بتواند به این ترتیب با دنیای خارج ارتباط برقرار کند. همچنین برای دسترسی به سایر نویسهها (include) هم به این محیط نیازمند است (مانند تگ <script>در HTML). (البته این یک ویژگی زبانی نیست اما در عمل اغلب این طور پیادهسازی شدهاست)
؛ تعداد متغیر پارامتر (variadic): تعداد نامعینی پارامتر را میتوان به یک تابع ارسال نمود. تابع میتواند هم از طریق پارامترهای رسمی و هم از طریق شی محلی arguments به آنها دسترسی داشته باشد.
- Literalهای آرایه و شی
مانند بسیاری از زبانهای نویسهای آرایهها و اشیاء (که در زبانهای دیگر همان آرایههای انتسابی هستند) را میتوان با یک نحو موجز ایجاد و توصیف نمود. در واقع این شیوهٔ نگارش پایهٔ قالب دادهای جیسون هم هست.
جاوااسکریپت به شیوهای مشابه زبان پرل از عبارات منظم پشتیبانی میکند که نحوی قدرتمند و موجز را به شکلی فراتر از توابع پیش ساخته برای کار با رشتهها، فراهم میکند.
نظام تایپ دهی
انواع زیر جزو انواع دادههای قابل دسترس در زبان جاوااسکریپت است. در استاندارد ECMA انواع دیگری هم تعریف شده که صرفاً داخلی است و برای پیادهسازی است.[۸]
تعریف نشده: این تایپ فقط یک مقدار با نام undefined دارد و متعلق به تمام متغییرهای مقدار دهی نشدهاست
نوع تهی: نوع تهی هم فقط یک مقدار دارد با نام null
نوع دودویی: نمایندهٔ یک مقدار منطقی است و دو مقدار true و false را میپذیرد.
نوع رشته: در بر گیرندهٔ تمام رشتههای متناهی از ۰ یا بیشتر عنصر ۱۶ بیتی بدون علامت است. این عناصر با اندیسهای نامنفی قابل دسترسی هستند. طول رشته تعداد عناصر داخل آن و طول رشتهٔ تهی برابر ۰ است.
زمانی که رشته حاوی متن واقعی باشد هر عنصر به عنوان یک واحد UTF-16 در نظر گرفته میشود (مستقل از این که شیوهٔ واقعی نگه داری رشته چه باشد). تمام عملیات بر روی رشتهها آنها را به عنوان اعداد صحیح بدون علامت در نظر میگیرند و تضمین کنندهٔ تولید رشته به حالت normalize شده نیست و تضمینهای خاص زمانی هم ندارد. علت این تصمیم گیری سادگی در پیادهسازی ذکر شدهاست.
نوع عدد: نوع عدد در جاوااسکریپت مطابق با استادارد IEEE برای اعداد شناور دودویی است (با اندکی تفاوت).
نوع شی: شی در جاوااسکریپت یک مجموعه بدون ترتیب از ویژگیها است. هر ویژگی میتواند داخلی، فقط-خواندنی، غیرقابل حذف، و غیرقابل پیمایش باشد (یا ترکیبی از اینها یا هیچکدام)
تبدیلات خودکار
این زبان دارای تبدیلات خود کار بین این انواع دادهای است.
زمانی که بخواهد یک if را ارزیابی کند یا از عملگرهای منطقی ! و && و || استفاده شود، تبدیل به نوع دودویی را انجام میدهد. مقادیر ۰ و ۰- و NaN به false و سایر مقادیر عددی به true نگاشت میگردد. همچنین رشتهٔ تهی false و سایر رشتهها true در نظر گرفته میشود. انواع شی و تابع true و undefined و null هم false در نظر گرفته میشود.
زمانی که یکی از عملوندهای عملگر + رشته باشد، تبدیل به رشته صورت میگیرد، مانند ۵ + “۳۷” که میشود “۵۳۷”
عملگرهای دیگری عددی (جز جمع) منجر به تبدیل به عدد میگردد مانند ۳ – “۵۷” که مقدار عددی ۳۴- را به دست میدهد.[۹]